Self-hosted Refact
Self-hosted version of Refact is a more flexible option with additional features. It allows you to create fine-tuned models for your specific task.
Self-hosted version is designed for developers who want to have a full control over their Refact experience.
Prerequisites
- Docker with GPU support
Installation
The easiest way to run this server is a pre-build Docker image.
Install Docker with NVidia GPU support. On Windows you need to install WSL 2 first, one guide to do this.
Run docker container with following command:
docker run -d --rm -p 8008:8008 -v perm-storage:/perm_storage --gpus all smallcloud/refact_self_hostingTo upgrade the docker, delete it using docker kill XXX (the volume perm-storage will retain your data), run docker pull smallcloud/refact_self_hosting and run it again.
Now you can visit http://127.0.0.1:8008 to see the server Web GUI.
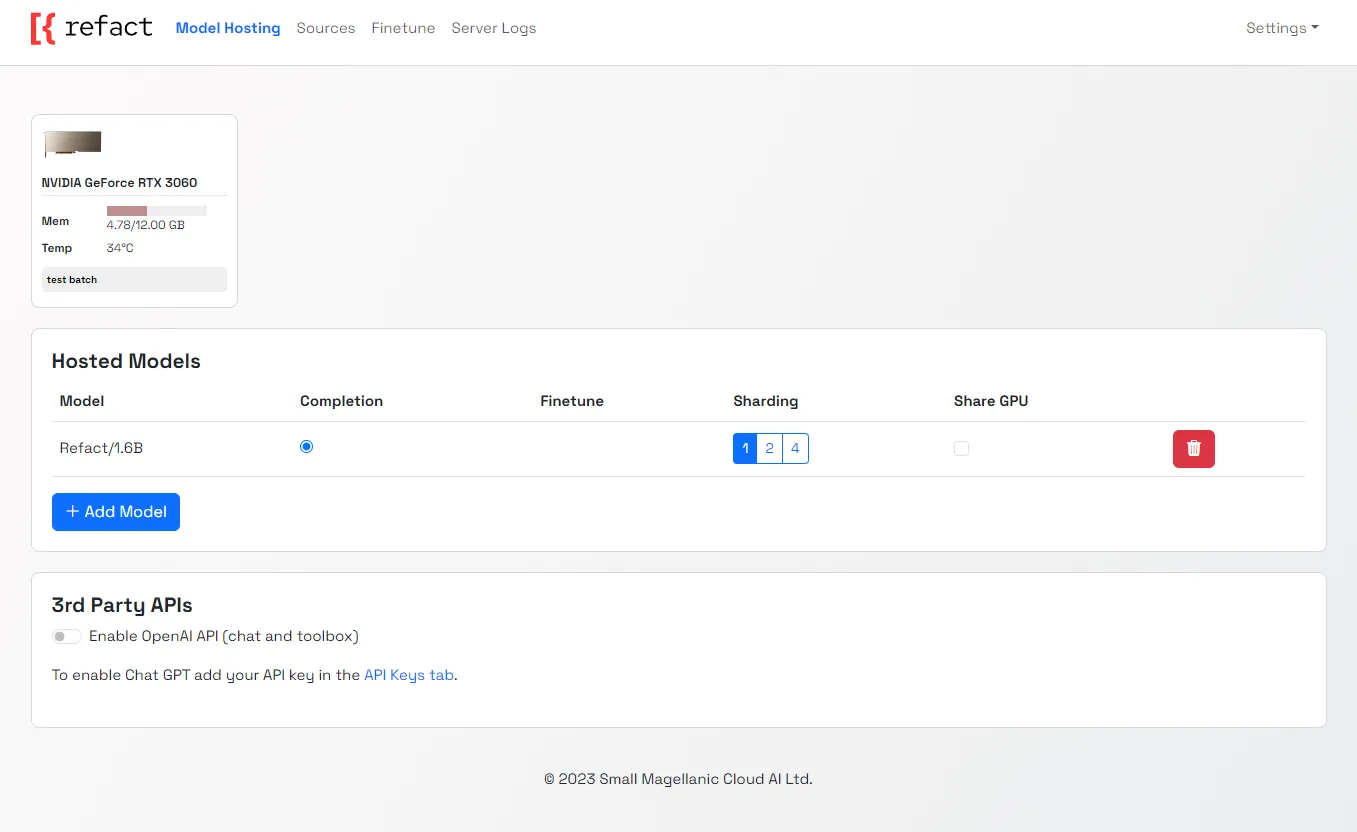
Sharding
You can choose to deploy a model to several GPUs with sharding. Select the number of GPUs that you would like to run your model on by selecting 1,2 or 4 in the sharding menu.
Shared GPU
To run several smaller models on one GPU, select the “share GPU” option from the menu next to the selected model.
Connecting OpenAI API
If you have an OpenAI API key, you can connect it to Refact and use GPT-series models inside Refact.
Custom Inference setup
Go to plugin settings and set up a custom inference URL http://127.0.0.1:8008
JetBrains
Settings > Tools > Refact.ai > Advanced > Inference URL
VSCode
Extensions > Refact.ai Assistant > Extension Settings > Infurl